对于AI发展和AI创业的一些random thoughts
前几天OpenAI研究员、普林斯顿大学博士 姚顺雨 写了一篇博客:AI的下半场(We’re at AI’s halftime)。我读后有一些启发,结合最近各大公司发布的模型、高校的论文,我把自己的一些想法记录一下。这是一个刚刚踏上AI门槛的人的一点random thoughts,不足一笑。
- 姚顺雨提出了目前LLM的一个成熟配方:pretrain + scaling + reasoning。这也是目前各个公司的训练范式。有趣的是,他又从RL的角度来解释了这个范式:pretrain = prior, reasoning = environment (原文说reasoning as actions,我还不是很理解)。这个解读的角度很有意思,我也很受启发。以前RL表现不好,是因为预训练的先验知识(prior)不够。人们以前总关注RL的算法,而忽视了先验知识和环境。
- 姚顺雨相信, AI当前已经进入中场。按照上面的配方,新的模型很快就会打败各种benchmark。这也是我最近的感觉,o3在 AIME 2025(美国高中生数学竞赛)上,在使用 Python 解释器辅助解题时,一次就做对的概率达到了惊人的98.4%。当时看到这个结果时,我和朋友一起开玩笑说,AIME 2025这个benchmark要没用了,得继续上升难度。在Gemini 2.5 pro和o3之后,很多benchmark都会被打败。
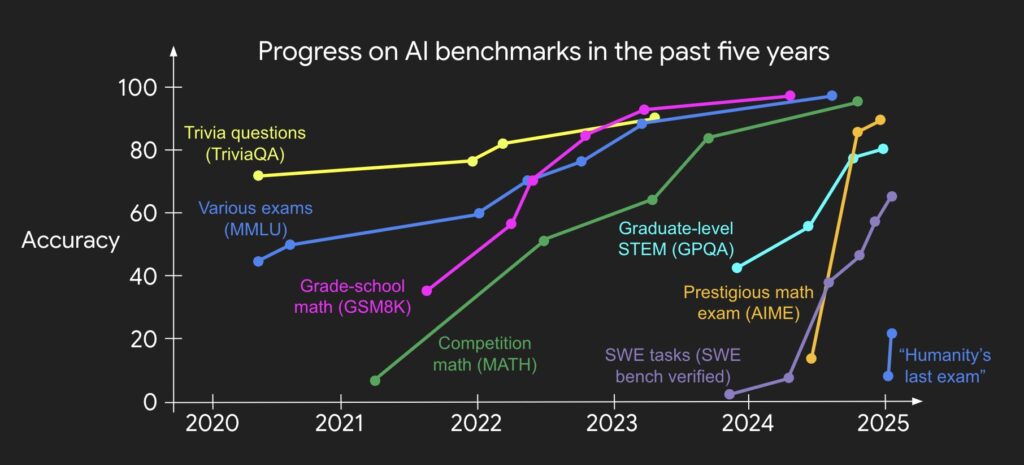
- 顺着这个思路,姚顺雨说,我们需要的不仅是新的、更难的benchmark,我们更需要新的benchmark setup机制、新的evaluation机制。他指出,目前evaluation机制和真实世界中的评估机制是不一样的,我们需要更贴近真实世界的评估机制。新的评估机制也能倒逼配方的更新。大神不愧是大神,很有见地!
- 后面两点是自己的感悟:除了新的评估机制意外,我觉得数据还可以做文章。OpenAI在4.5的采访中提到提高“数据效力”问题,我觉得这是目前业界亟需解决的。算力可以继续增加、电力也可以增加,但新的数据怎么来呢?OpenAI说他们想要从现有的数据中挖掘出更多的知识来(原文:数据压缩即知识)。网络留言说:xAI的1200多名员工中有1000人是负责和数据相关工作的。可想而知,对一个LLM公司而言,数据多么重要。我觉得这里面是有创业可能的:1)简单的路径:如果你知道这些公司想要什么样的数据,那你就可以成立一家公司,帮忙把数据处理成这个样子(比如Alexandr Wang的Scale AI,大家笑话这家公司没有技术,但他们却解决了OpenAI这类有技术的公司的数据痛点问题);2)困难的路径:假如你知道怎么从有限的数据中压缩出更多的知识,那也可以创业了。
- AI的创业才刚刚拉开帷幕。姚顺雨在博客的最后说到“下半场的参与者可以通过构建有用的产品来建立价值数十亿甚至数千亿美元的公司”。对此我深表赞同,在AI的上半场,是大模型的竞争,是算力的竞争,并没有很多创业机会留给普通人。但现在大模型竞争格局愈发清晰,模型本身智能程度更高了,模型工具化、在各个产业落地的可能性大大提高。而且大厂也努力开发各种产品,想让自己的模型工具化。我觉得直到现在,我们才开始迎来了利用AI广泛创业的可能性。将会有新的公司,利用AI开发出好的产品,在这个时代脱颖而出,和当初的谷歌一样。我朋友说,现在市场上已经有很多AI技术解决方案的提供商,比如Cohere(Cohere创始人是transformer作者中唯一一个学生,多大的PhD。值得一提的是,他写transformer时还在多大读本科)。我觉得完全不需要担心,这个市场太大了,我们就算只分得这个巨无霸蛋糕的边角料,也会被撑死。关键是你和你的朋友,有没有能力和勇气去做出点好东西。
未完待续。。。。。。20250423